Azure SQL Database のサービス概要
Azure SQL Database
前回の記事「Terraform で Azure SQL Server」で Azure SQL Database を構築しました。そこで分かったことは、Azure SQL Database の全体像がいまいち分からないということでした。
Managed Instance やサーバーレス形式など、同じ SQLServer でも複数のサービスが存在します。また、課金形態も DTU と vCore 購入モデルという2つのパターンが存在します。
さらに、サービスレベル(Basic/Standard/Premium)という分類とそれに応じた高可用性の仕組みが別々に存在したり、ただの SQLServer でどうしてこんなにも複雑なのかと思ってしまいます。
今回はそんな Azure SQL Database を簡単にまとめてみました。
Azure SQL Database は3つの PaaS から成る
SQL Server の基本構成
まずは、前提として SQL Server がどういったアーキテクチャとなっているか確認します。サーバー、インスタンス、データベースの構成は概ね以下のようになっています。

1つのサーバーに複数のインスタンスを構築することができます。インスタンスの中身は、システムデータベースとユーザーデータベースに分かれています。
システムデータベースでは、インスタンスのタイムゾーン、言語、ジョブといった設定情報の格納や、一時テーブルによる中間処理が行われています。ユーザーデータベースには、文字通りユーザーが利用するデータが格納されています。
※システムデータベースの詳細についてはこちらを参照ください。
※今回は Contained Databases についての詳しい説明は省いています。Contained Databases と Contained Databases User の概念については、別の機会に解説したいと思います。
Azure SQL Database は3つの PaaS から成る
一方で Azure SQL Database は以下のようなサービスの構成をとっています。
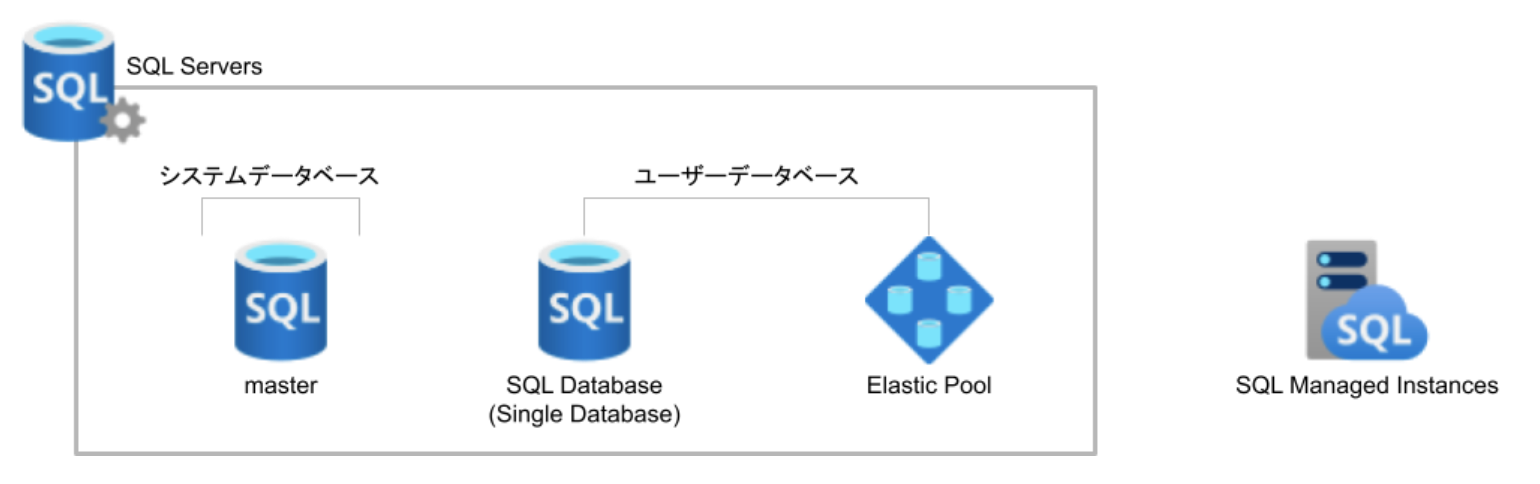
上記の図で示したかったことは、SQL Database(Single Database) と Elastic Pool と Managed Instance の違いです。
SQL Servers というリソース(インスタンス)を構築し、その上に SQL Database(Single Database) と Elastic Pool を構築することができます。そして、それとは全く別で、Managed Instance は単独で SQL Server を使えるサービスとなっています。
3つの PaaS の特徴
| PaaS サービス名 | 詳細 |
|---|---|
| SQL Database(Single Database) | 最もシンプルなサービスです。Azure 上で SQL Server のデータベースが利用できます。データベースに対する操作は全て可能ですが、OS、インスタンスレイヤーの設定変更はできません。タイムゾーンは UTC で固定です。 |
| Elastic Pool | 複数の SQL Database(Single Database)を同じリソース上で利用することが可能です。各データベースのピークタイムが異なれば、データベース単独で利用するよりもリソースを無駄なく活用できることになりますので、コストメリットを出すことが可能です。 |
| Managed Instance | インスタンスとデータベースが一体となったサービスです。ハイパフォーマンスなストレージも利用できます。SQL Database より制約が少なく成るため、オンプレから移行しやすいといったメリットもあります。 |
Azure SQL Database の課金
Azure には同じ SQLServer でも複数の PaaS が存在することは説明しました。続いては課金形態ですが、これも結構複雑です。
AWS は CPU や Memory とストレージの容量に応じて課金される仕組みです。Azure も原則は同じです。しかし、SQL Database には DTU購入モデルという課金形態も存在しますので、まずはそこの理解が必要です。
DTU と vCore
DTU購入モデルとvCore購入モデルの選択の内容をもとにざっくり説明します。
| 購入モデル | 詳細 |
|---|---|
| DTU | DTU(Database Transaction Unit)とは CPU, Memory, DiskIO を丸めたもので、サービスレベルによって性能が上下します。サービスレベルは「Basic・Standard・Premium」と存在します。 詳細は DTU購入モデル を参照ください。 ※ライセンス込みの従量課金となっています。 |
| vCore | コア数とストレージとハードウェアを指定するものです。メモリーは選択するハードウェアの種類により決められています(例:仮想コアあたり 5.1 GB)。 サービス階層「General Purpose・Business Critical・Hyperscale」なるものが存在します。 詳細は vCore購入モデル を参照ください。 ※コア数あたりのライセンス費用が発生しますが、BYOLの場合は割安になります。 |
サービスレベル/サービス階層
各サービスレベル、サービス階層の詳細については以下のリンクを参照ください。
サーバーレス ※vCore購入モデル かつ General Purpose にのみ存在
サーバーレスでは、ワークロードの需要に基づいてコンピューティングが自動的にスケーリングされ、1秒あたりのコンピューティング使用量に対して請求されます。
アイドル期間にデータベースを自動的に一時停止し、その間はストレージのみに課金されます。再びアクティブになると自動的にデータベースが再開され、コンピューティング使用量に対する課金も再開します。
普段はあまり使われていなく、起動時の遅延も許容できる場合には適しています。普段はあまり稼働しないが、ピーク時にはスケールアウトしてくれる、予測不可能なサービスには適しているのではないでしょうか。
詳細は Azure SQL Database serverless を参照ください。
Azure SQL Database の高可用性
SQL Database の高可用性の目標値
Azure SQL の高可用性に関するドキュメントには以下のように書かれています。
Azure SQL Database と SQL Managed Instance での高可用性アーキテクチャの目的は、メンテナンス操作や障害の影響を心配せずに、データベースの稼働および実行の時間が 99.99% 以上になるように保証することです。
Azure SQL Database の基本となるデータベースがパッチを適用されるか、またはフェールオーバーした場合、お使いのアプリで再試行ロジック(※1)を使用していれば、ダウンタイムは認識されません。
SQL Database と SQL Managed Instance は、クリティカルな状況であっても迅速な復旧が可能であるため、データが常に使用可能であることが保証されます。
※1 再試行ロジックとは接続失敗時に再度接続を行うようプログラムされていること。
つまり、SQL Database と SQL Managed Instance では 99.99% の高可用性を保証しており、アプリ側で接続エラー時の再接続ロジックを入れておけば、フェイルオーバー発生時においてもダウンタイムなく利用できる、ということです。
そして、高可用性の仕組みは大きく4つあります。「Standard(ローカル冗長化構成)」と「Standard(ゾーン冗長化構成)」と「Premium(ローカル冗長化構成)」と「Premium(ゾーン冗長化構成)」です。
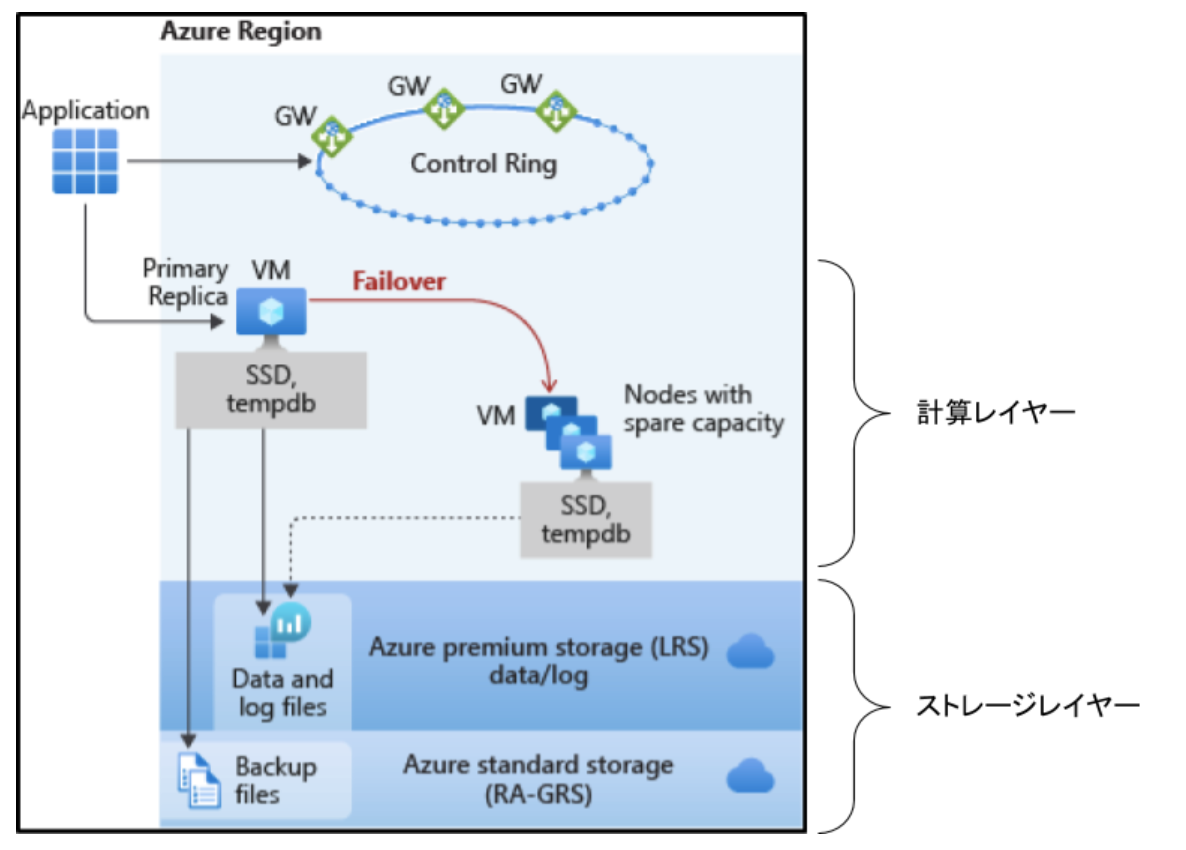
Standard(ローカル冗長化構成)
計算レイヤーはローカルでフェールオーバーする仕組みとなっていて、データレイヤー(ログファイルとデータファイル)は Azure Premiun Storage の LRS(ローカル冗長ストレージ)に配置されています。
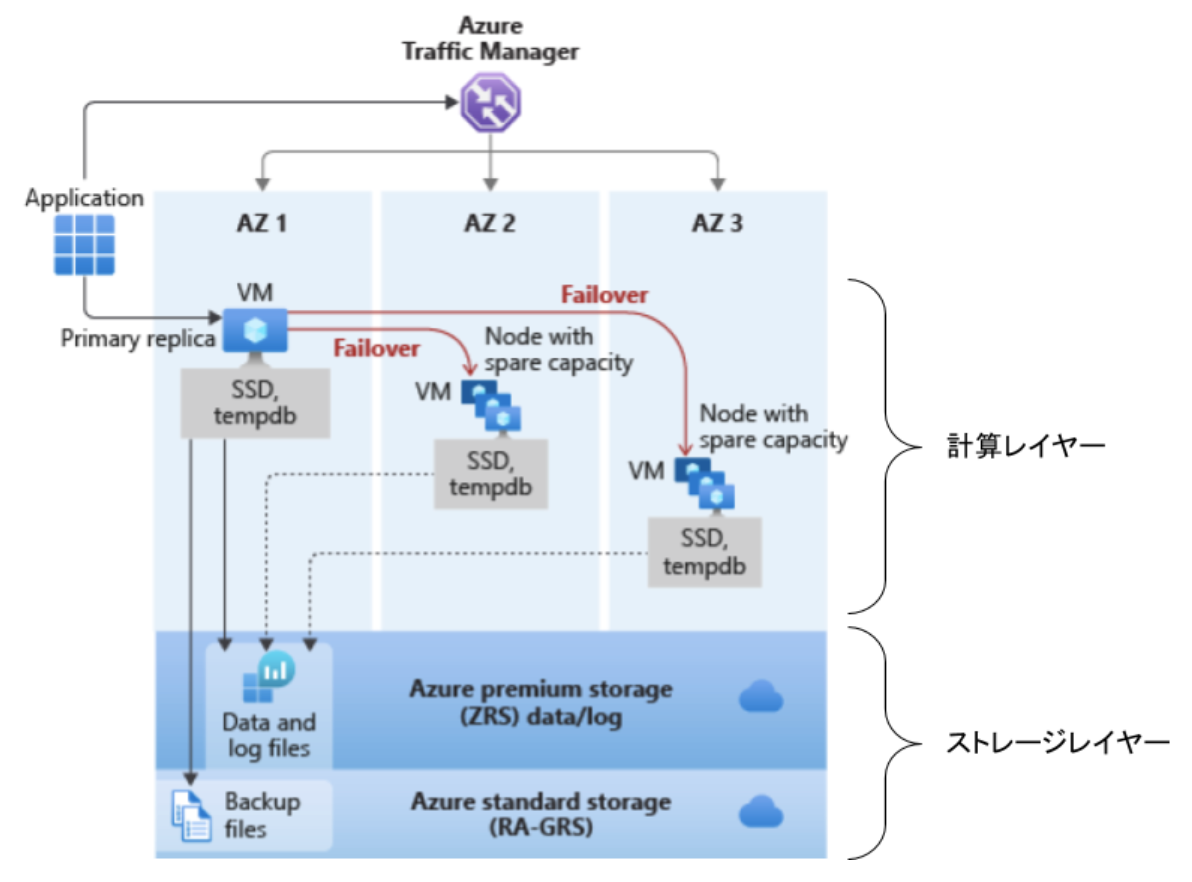
Standard(ゾーン冗長化構成)
計算レイヤーは3つのゾーンでフェールオーバーする仕組みとなっていて、データレイヤー(ログファイルとデータファイル)は Azure Premiun Storage の ZRS(ゾーン冗長ストレージ)に配置されています。
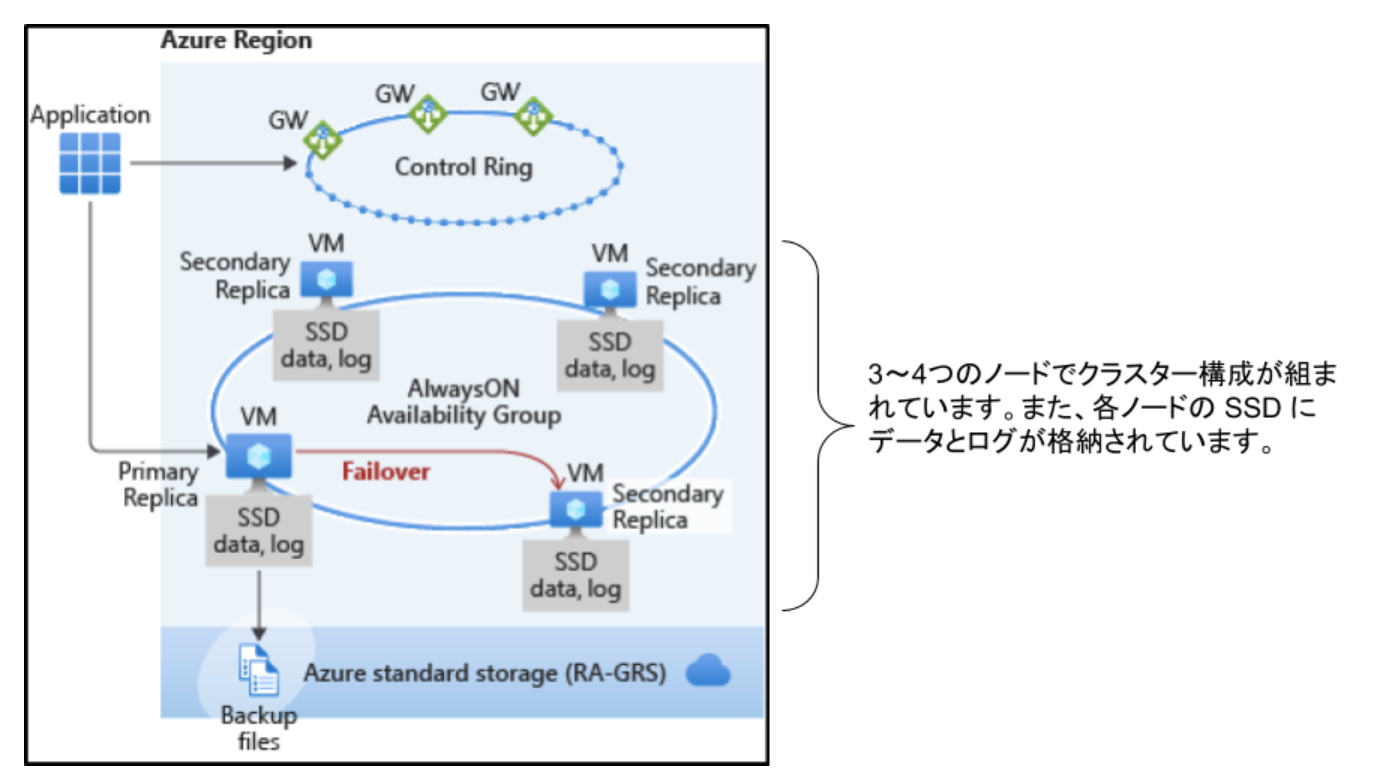
Premium(ローカル冗長化構成)
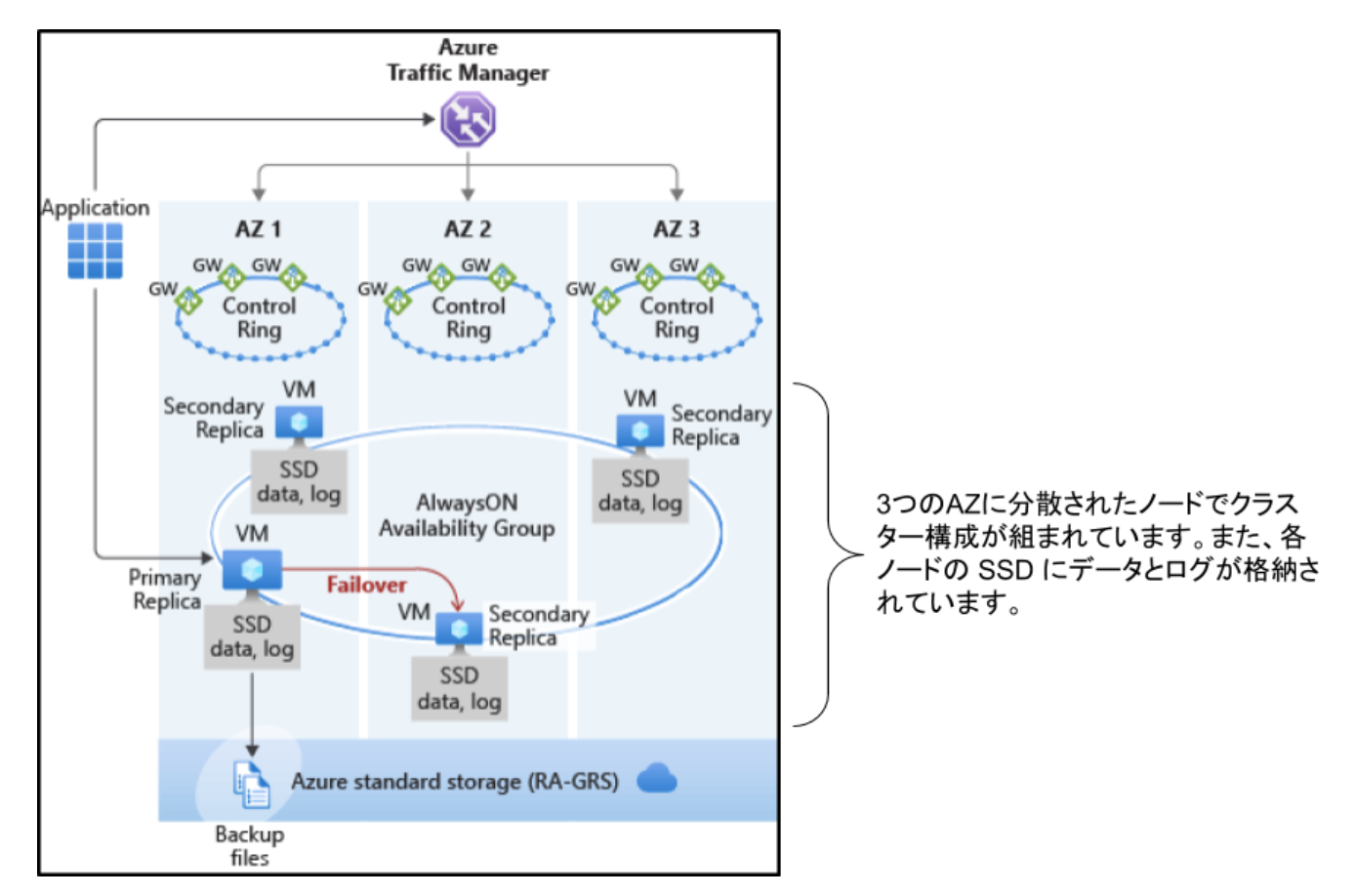
高可用性は、SQL Server Always On 可用性グループと同様のテクノロジを使用して実装されます。
クラスターには、読み取り/書き込みの顧客ワークロードにアクセス可能な単一のプライマリレプリカと、データのコピーを格納する最大3つのセカンダリレプリカ (計算とストレージ) が含まれます。プライマリノードは常にセカンダリノードへ順番に変更をプッシュし、各トランザクションをコミットする前に少なくとも1つのセカンダリレプリカにデータが同期されるようにします。
このプロセスによって、何らかの理由でプライマリノードがクラッシュした場合に、フェールオーバー先となる完全に同期されたノードが常に用意されている状態が保証されます。
また、Read scale-out といって、読み取り/書き込みレプリカ上で実行する代わりに、読み取り専用レプリカのいずれか1つのコンピューティング能力を使用して読み取り専用ワークロードをオフロードできます。これにより、読み取り専用のワークロードを読み取り/書き込みワークロードから分離でき、パフォーマンスに影響が及ぶことがありません。
Premium(ゾーン冗長化構成)
Premium(ゾーン冗長化構成)では、追加のデータベース冗長性を作成しないため、追加料金なしで使用できます。ゾーン冗長構成を選択することで、アプリケーションロジックにまったく変更を加えずに、データセンターの壊滅的な障害などの極めて大規模な障害に対して、データベースが回復性を備えることができます。
なお、ゾーン冗長データベースでは、離れた距離に位置するさまざまなデータセンターにレプリカがあるため、ネットワーク待機時間が長くなるとコミット時間が増大し、一部の OLTP ワークロードのパフォーマンスに影響を及ぼす可能性があります。その場合は、いつでもゾーン冗長設定を無効にして単一ゾーン構成に戻すことができます。
おまけ 自動フェールオーバーグループ(リージョン間レプリケーション)
ローカル、ゾーン、ときたらリージョン間でフェールオーバーできる構成はないのか、と思いますよね。もちろんありました。
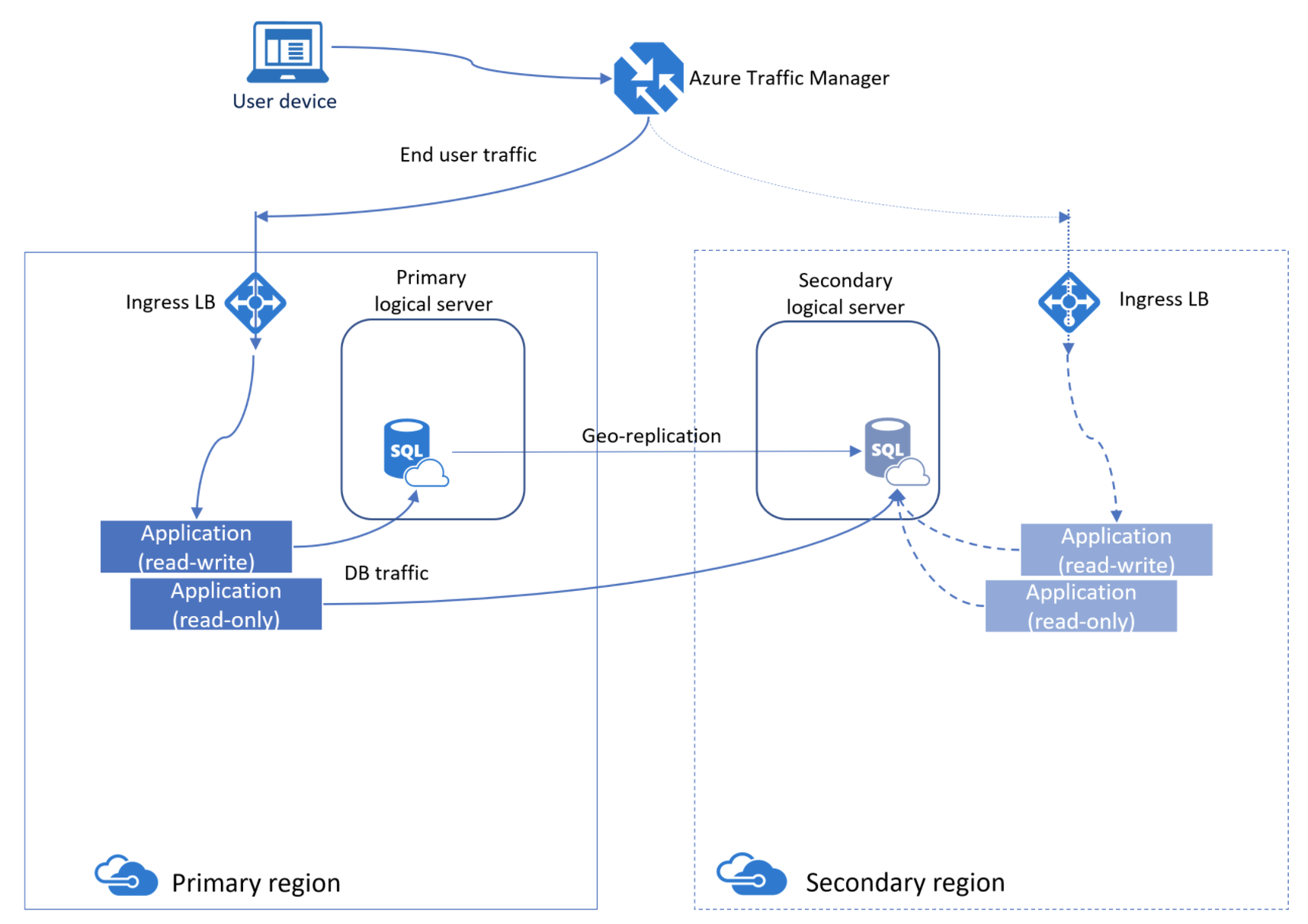
アクティブ geo レプリケーションと言う Azure SQL Database の機能です。これを使用すると、同じデータセンターまたは異なるデータセンター (リージョン) 内のサーバー上に、個々のデータベースの読み取り可能なセカンダリデータベースを作成することができます。
下記のような構成を自分で設定しなければいけないので、ボタン一つで作成というわけにはいかないようです。
以上が SQL Database の高可用性の仕組みです。
Azure SQL Database のスペック一覧 ※2021年1月9日時点
考慮すべきは5つの要素
Azure SQL Database を立てるにあたって、どのようなスペックを選択すべきか、考慮すべきは以下の5要素です。
- 課金モデルの選択
- サービスの重要度(サービスレベル/サービス階層)
- ハードウェアの種類
- ストレージ最大容量
- 高可用性の領域(ローカル、ゾーン)
Azure SQL Database のスペック一覧
SQL Database には、どのようなスペックが用意されているのか、上記の5要素をもとに一覧を作ってみました。
| 購入モデル | レベル/階層 | スペック/ハードウェア | Max Storage | 高可用性 | |
|---|---|---|---|---|---|
| DTU | basic | DTU = 5 | 2GB | [Standard] LRS | |
| Standard | S0 | DTU = 10 | 250GB | ||
| S1 | DTU = 20 | ||||
| S2 | DTU = 50 | ||||
| S3 | DTU = 100 | 1TB ※250GBまで追加料金なし ※250GB以降追加料金あり 0.17USD/GB | |||
| S4 | DTU = 200 | ||||
| S6 | DTU = 400 | ||||
| S7 | DTU = 800 | ||||
| S9 | DTU = 1600 | ||||
| S12 | DTU = 3000 | ||||
| Premium | P1 | DTU = 125 | 1TB ※500GBまで追加料金なし ※500GB以降追加料金あり 0.34USD/GB | [Premiu] LRS or ZRS Read scale-out | |
| P2 | DTU = 250 | ||||
| P4 | DTU = 500 | ||||
| P6 | DTU = 1000 | ||||
| P11 | DTU = 1750 | 4TB ※4TBまで追加料金なし | |||
| P15 | DTU = 4000 | ||||
| vCore | General Purpose Serverless | Gen5 | Max vCores => 1 - 4 Memory = vCores × 3GB | 1TB ※0.12USD/GB | [Standard] LRS |
| Max vCores => 6 - 10 Memory = vCores × 3GB | 1.5TB ※0.12USD/GB | ||||
| Max vCores => 12 - 20 Memory = vCores × 3GB | 3TB ※0.12USD/GB | ||||
| Max vCores => 24 - 40 Memory = vCores × 3GB | 4TB ※0.12USD/GB | ||||
| General Purpose | Gen5 | vCores => 2 - 4 Memory = vCores × 5.1GB | 1TB ※0.12USD/GB | [Standard] LRS or ZRS | |
| vCores => 6 - 10 Memory = vCores × 5.1GB | 1.5TB ※0.12USD/GB | ||||
| vCores => 12 - 20 Memory = vCores × 5.1GB | 3TB ※0.12USD/GB | ||||
| vCores => 24 - 80 Memory = vCores × 5.1GB | 4TB ※0.12USD/GB | ||||
| FSv2 | vCores => 8 - 14 Memory = vCores × 5.1GB | 1TB ※0.12USD/GB | [Standard] LRS | ||
| vCores => 16 - 24 Memory = vCores × 5.1GB | 1.5TB ※0.12USD/GB | ||||
| vCores => 32 - 36 Memory = vCores × 5.1GB | 3TB ※0.12USD/GB | ||||
| vCores => 72 Memory = vCores × 5.1GB | 4TB ※0.12USD/GB | ||||
| Business Critical | Gen5 | vCores => 2 - 4 Memory = vCores × 5.1GB | 1TB ※0.25USD/GB | [Premium] LRS or ZRS Read scale-out | |
| vCores => 6 - 10 Memory = vCores × 5.1GB | 1.5TB ※0.25USD/GB | ||||
| vCores => 12 - 20 Memory = vCores × 5.1GB | 3TB ※0.25USD/GB | ||||
| vCores => 24 - 80 Memory = vCores × 5.1GB | 4TB ※0.25USD/GB | ||||
| Hyperscale | Gen5 | vCores => 2 - 80 Memory = vCores × 5.1GB | 100TB ※0.1USD/GB | Replicas 1 - 4 | |
最後に
Azure SQL Database は奥が深いですね。複雑のようですが、全体像がわかってくると、ニーズに合わせて柔軟なサービスレベルを選択することが可能ですし、課金形態も複数用意されているのでコスト最適化も測ることが可能になっていると思います。
また、ネットワーク構成についてもパブリック接続、プライベートエンドポイントを使った閉じた接続など、色々とできますので、割と要件に合わせて柔軟な設定ができるのではないかと思っています。
まだまだ、掘り下げるべき内容がありますので、今後も Azure SQL Database の記事は書いていきたいと思います。